Rewriting moviegolf.com
In April, I relaunched moviegolf.com, a website I’ve operated since 2009. Since this is one of the flashier programs I’ve written and certainly one of the longest-lasting, I wanted to recount its history. My style of programming has definitely shifted in the intervening years.
What is Movie Golf?
From the site’s about page:
Movie Golf is a movie trivia game — like Six Degrees of Kevin Bacon — that involves connecting movies. The object of the game is to connect two seemingly different movies by putting the fewest intermediaries. To putt to another film, you must find a common actor. For example, you can putt from “Legally Blonde” to “Pleasantville” via Reese Witherspoon.
It’s a game my dad (Jeff Light) and his friends at OSU developed many years ago, but it boils down to a basic CS graph problem: find the optimal path between two movie nodes where each edge is an actor.
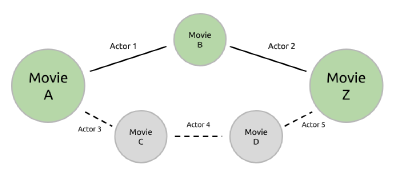
An undirected graph connecting Movie A to Movie Z. The optimal path goes through Movie B, with Actor 1 connecting Movie A to Movie B and Actor 2 connecting Movie B to Movie Z. In order for an edge to exist between two movies, the actor must have been in both movies. The bottom shows a suboptimal path, going from Movie A to Movie C to Movie D to Movie Z. There are often many ways to traverse between two movies.
Version 1.0
I originally wrote a Python solver for this game back in early 2009. At the time, I was quite enamored with Freebase and noticed that I could download a medium-sized file (couldn’t have been more than a few dozen megabytes) and get information on about roughly 60,000 movies. This included cast listings, directors, and cinematographers. Everything. Remembering this game my dad taught me, I coded up a hacky command-line solver that would read the whole dump into a hash map and then find the path between two given movies. I showed this to my friends, who were excited, but understandably wanted a more accessible way to play the game. Since I was on an App Engine + Django kick at the time, a website seemed the way to go.
For those who haven’t used App Engine, it spins up virtual server instances in response to how much traffic you use and shuts them down when you’re not using them. The cost of “read an entire multi-megabyte file from disk on startup” per instance didn’t seem like a good idea to me back then. Nowadays, I wouldn’t bat an eye, but back then, I didn’t have a grip on relative speeds of things. So I decided “hey I should put this in a database”. This was a good idea; this is what I do in the new version. The cringeworthy idea (in hindsight) was my choice of database: I used Cloud Datastore. Don’t get me wrong: Datastore is a fine storage system, but it is not relational, which is precisely what a problem like Movie Golf requires. To find adjacent films, I was issuing a query per actor in a film. To put this in perspective, assume that on average movies have: (all handwaving, but roughly true) 3 actors in them, connect to 90 other movies, and have an overlap factor of 50%. Connecting a pair of movies with two intermediaries would requiring querying Datastore over a network 12,423 times! Even if each query was 1 millisecond, this would be over 12 seconds of wall-clock time. By comparison, my new system only issues a fraction of the queries, all in-memory.
While it’s easy for me to pick on myself now, these decisions were made because I did not understand the underlying systems I was using. I did not learn about SQL joins until many years later. When I gave up on using App Engine, I wrote a small on-disk B-tree index that would store the adjacent films directly. Little did I know, this is exactly what SQL databases do under the hood.
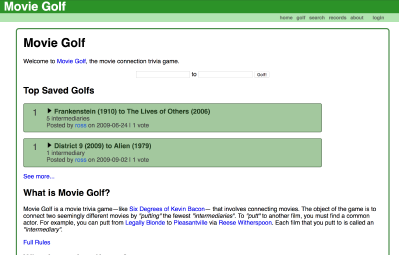
A screen capture of moviegolf.com’s landing page, circa 2013. Very minimalist. The search form at the top is where you type in two movies. I also tried to provide a logged-in experience where you could save and vote on golfs, but I was the only one who ever did.
The site worked well enough and supported a variety of movie-related queries. However, it had one key disadvantage: the data was never up to date. You could search for a particular movie and click a button to refresh that single movie. This didn’t scale at all and required manual end-user effort. When you’re trying to surface connections during a golf search, you want movies you didn’t ask for to be updated. Over time, movies become more connected, since new movies will bring together actors in new ways. But at least there was some data.
As a novice, I was satisfied.
8 Years Later…
In 2010, Google acquired Freebase. Five years later, Freebase was shut down. moviegolf.com no longer had any data. Look on my website, ye Mighty, and despair!
With one formal Computer Science degree and 4 years of work experience under my belt, I decided that I wanted to replace the derelict website. My priorities were to study the Go on Google Cloud Platform experience and to keep any ongoing maintenance effort to a minimum. My free time is at a premium, so everything should be simple, write-once, and easy to debug.
Data Ingestion
Getting the data was by far the most complicated part of the whole endeavor and the major factor that kept me away from this rewrite. I had to find a new data source and this time, I wanted it to be as live as possible. No more manual updates and no more hosting of user-generated content. Let somebody else be moderator. IMDB was the obvious candidate, and they do publish data dumps, but I was unclear as to whether their licensing terms would fit my use case. Getting a lawyer for connecting movies seemed absurd. When Freebase was shut down, their data was migrated to Wikidata. This seemed perfect: a data model I already understood with weekly dumps, an API for fetching recent changes, and a CC0-licensed corpus.
Since most of the other interesting bits (actually golfing, showing data via HTML) required data, and using real data tests the system more than fake data, I took a week and built this first. The Wikidata dumps come as compressed JSON records, one per line. The uncompressed corpus is 1.7 billion entities, taking up 111 gigabytes! While this sounds infeasibly large, I only want a small fraction of that data: just the movies and actors. While the records for films have obvious indicators in the stream, Wikidata does not provide an indicator for actors. To determine which entities are actors, you must keep a running list of which record IDs show up in the cast of each film. As such, my importer needed to walk over the data once to just find out which records it should keep, then walk over the data again to collect these records into a database. Once the code was tested and built, it took about an hour to download and decompress the dump, and then an hour and a half to run the importer. Most of this is disk-bound, so I could have benefited from a higher speed disk on my desktop. This was good enough to get initial development going: a 40 megabyte corpus with real data.
Updating the Data
However, downloading the dumps every week would obviously be impractical because of both time and space restrictions. I’d have to pay for far more cloud storage than I’d actually need and the data would be quite stale. Further, the longer it takes for a single conceptual operation to take place, the more likely it is for something to kill that job in the middle. Yay Murphy’s Law! Instead, as I alluded to above, I wrote another service (the updater) that consults the Wikidata recent changes API to see the entities that were modified since the last import and then read the changes directly from the website instead of the dumps. In my small-scale tests on my laptop, I noticed that it took roughly 1 minute to process 500 entity changes (the vast majority of them are not even movie related). I measured the number of changes that are made in a 24-hour period and found it to be roughly 160,000, which is about 7,000 changes per hour. I wanted each import run to take less than 10 minutes, so I decided to run the updater job every 30 minutes.
You may notice a problem here: what if the updater starts lagging behind? Let’s say the updater crashes on one or more of the runs. It could then start taking on a larger than normal workload, thus causing it to miss the next scheduled run because it was still running. And further, when I go to cut over from the initial dump import, how do I catch up with the roughly 3 hours that were missed while the dump was being imported? To solve these concerns, I specify a maximum time span that any one import can operate on. I chose a value that’s a little over the run frequency: 45 minutes. This way, the system will have a much more predictable load, even when it’s playing catch-up. As long as it doesn’t run more than 30 days behind (the Wikidata recent changes limit), then it’s fine.
Having done all this, I started looking at hosting.
Price-Driven Architecture
One of the most surprisingly useful tools in the GCP repertoire is the Pricing Calculator. It allows you to plug in your predicted usage and get an idea of how your bill would increase. Scaling in some ways are more expensive than others. Load balancing is the most expensive, with CPU and RAM running a close second. Storage is cheap. Without the calculator, I wouldn’t have had a prayer of making these decisions without months of billing trial-and-error with redesigns.
Pricing also forced me to simplify my initial design. Originally, I thought I would use Cloud PostgreSQL, but even running an out-of-SLA shared instance was more expensive than I wanted. To avoid the Cloud PostgreSQL instance, I settled on storing a SQLite database in Cloud Storage. The live serving traffic only ever needs to read from the database, so there’s no write contention. This way, I could use the production data during local development. This also simplified my integration tests, as I didn’t need to stand up a full SQL server, just a file.
After working at Google for years, I have become accustomed to “N + 2” redundancy: always deploy with 2 more instances than you need to run the service. This allows you to handle a planned instance outage (upgrading your service) and an unplanned outage (something dies). This is fine if you need to be highly available and can afford the resources. But moviegolf.com does not need to be high-availability. moviegolf.com’s budget is out-of-pocket (i.e. “as low as possible”). While I would love to be running moviegolf.com with even 99% reliability, a much more reasonable Service Level Objective would be 90%. N = 1 it is.
Lesson learned as a GCP hobbyist: you want to run the least number of instances possible, even if you pack slightly more into that one instance. This rules out Google Container Engine, since it runs on multiple nodes. I also ruled out App Engine (Flex or Standard) for my project, since I wanted to split apart the functionality into multiple Docker images. My reasoning: if I want to scale up in the future, I don’t want to rule out Container Engine. Even though the pricing limited me in some regards, it forced me to examine important trade-offs for my solutions. Even though my potential load is small now, I have a scaling plan.
Given these constraints, I developed two Go servers in addition to the Updater I outlined above. These all run in separate Docker containers on one Google Compute Engine instance.
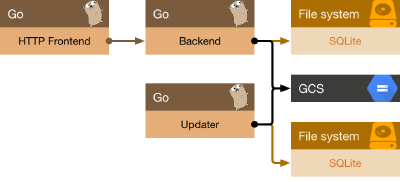
Three Go services (the HTTP Frontend, the Backend, and the Updater). Both the Backend and the Updater obtain a SQLite database from Google Cloud Storage.
Frontend and Backend
Once I had the data from the dump importer in a SQL-queryable form, the backend server was straightforward to write. It is an RPC service that downloads the SQLite file from Cloud Storage and then runs queries to find the optimal golf between movies. It uses a simple breadth-first search. The advantage of splitting this out as a separate binary is for ease of integration testing, and also ease of scaling. You could imagine that when I scale up, I could start giving more CPU cores to backend services, while continuing to have a minimal set of resources for the frontend. The frontend is similarly straightforward: take HTTP requests, translate them into backend requests, and then render HTML. Once the data is available, the rest is easy.
For debugging, I integrated both of these servers with Stackdriver Logs and Stackdriver Tracing. Stackdriver Log Metrics are good enough to act as a whitebox monitoring source, so I can monitor increases in 500-level HTTP error responses. These out-of-the-box tools are what make GCP rock.
DevOps Time!
To deploy this, I used Google Compute Engine directly. I used the new Container-Optimized OS, so I could run my stateless Docker jobs — notice how Google Cloud Storage is the only service with mutable state. Frontend, backend, and updater only have local caches of the database, so they are entirely disposable. I can update the site by creating a fresh instance and deleting the old one, although in practice, I just update the systemd units and restart the services. Again, if I could use a load balancer, this would be easier.
One unfortunate side-effect of using Google Compute Engine is that it is up to you, the DevOp, to plumb logs into Stackdriver Logs. While there does exist a Logging Agent, it is intended to be used in a non-Dockerized environment. To work around this, I ended up creating a systemd unit that would pipe journalctl output to a FIFO, another systemd unit that would send the pipe’s data to a google-fluentd Docker container via stdin, and then using a google-fluentd config that sends stdin to Stackdriver. The google-fluentd config (the hardest part) looks like this:
But as a friend pointed out to me, I should probably just rip google-fluentd out and write a custom log forwarding job in Go. A task for another day! If I was running in a more supported configuration, this would have been easier. As is, it was relatively easy to get this running on GCP.
Lessons Learned
In short, my experience has taught me to always be mindful of tradeoffs when designing — whether that be on simplicity, reliability, price, resource usage, or speed. The set of tradeoffs I consider has broadened over time. The newer version of Movie Golf has more parts, but each part conceptually does one thing that can be tested and can fail independently. An understanding of how data storage systems work has definitely helped guide me to a better design. But it’s interesting how close my final approach is to my first approach: load a file into memory and run the golf queries. For me, that’s been the greatest lesson I’ve learned: only add essential complexity.